
I wrote a post about how we scaling AWS Aurora at ticketea when we go to sell some big event.
Originally it was available on our engineering blog: Scaling Amazon Aurora at ticketea, but I gonna include in this blog too.
Ticketing is a business in which extreme traffic spikes are the norm, rather than the exception. For Ticketea, this means that our traffic can increase by a factor of 60x in a matter of seconds. This usually happens when big events (which have a fixed, pre-announced 'sale start time') go on sale.
Cloud elasticity has its limits, particularly when reacting to extremely sudden changes in the inbound request rate. This is the reason why, for certain situations, we prefered to perform a pre-planned platform scaling followed by a warm-up.
For the sake of context, we host our infrastructure in AWS ad we're heavy Amazon Aurora users.
For Ticketea, a big event usually translates to a surge of traffic, which touches the following components:
- Frontend app servers serving ticketea.com
- API app servers
- Background tasks
- Relational Databases
The first three resources are easy to scale horizontally (add / remove EC2 instances). We just need to modify their autoscaling groups, and AWS will do the hard work for us.
Relational databases are usually much harder to scale. Even though we're using an AWS Aurora cluster, with multiple read replicas, scaling up and down the writer node is usually the tricky part. Before we get into it, let's talk a bit about AWS Aurora and how we're using it.
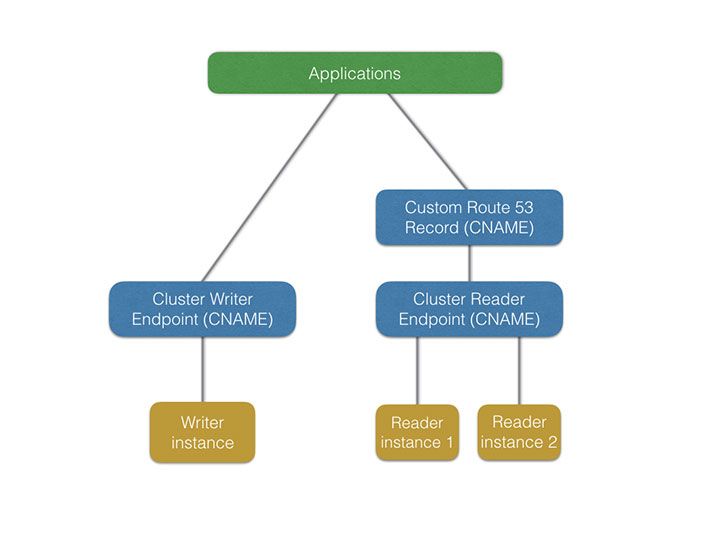
An Aurora cluster is accessible through two DNS records:
- A writer endpoint (a DNS Record pointing to the currently elected writer node)
- A reader endpoint (a DNS Record which balances among the reader instances)
Understanding the failover process
Failover is the process that Amazon Aurora gives us to promote a node to the writer role (Aurora only allows one writer at a time). The choice of the future writer node is performed using tiers. A tier is a config value which is set at instance creation time (and can be changed later).
When a failover happens (either manually triggered or in reaction to a cluster failure) Aurora will promote the lowest-tier reader node to the writer role.
As stated before, sometimes we need to scale the writer node vertically. To achieve this result, we force a failover to a beefier instance. Traditionally, we used to do this when the traffic was at its lowest point during the day, because we were afraid of the impact that such operation might have had on our users.
That really didn't work out well for the team (it meant that someone had to wake up early / stay up late), so we decided do some tests to understand how to improve the failover and recovery times.
The first step was a simple script that issued bursts of queries to the writer node. During the execution, we would perform a manual failover, at which point we'd start to see that some of queries were OK, but others failed randomly. The errors lasted during a 10-15 second window. We repeated the test several times, and results were similar.
We decided to investigate how the Aurora writer and reader endpoints were implemented. Running host on the writer endpoint DNS record (let's suppose tkt-aurora-cluster.cluster-abcdefg.eu-west-1.rds.amazonaws.com), reveals that the endpoint is really a CNAME pointing to the currently elected Aurora writer instance.
$ host tkt-aurora-cluster.cluster-abcdefg.eu-west-1.rds.amazonaws.com
tkt-aurora-cluster.cluster-abcdefg.eu-west-1.rds.amazonaws.com is an alias for
tkt-aurora-1.abcdefg.eu-west-1.rds.amazonaws.com
tkt-aurora-1.abcdefg.eu-west-1.rds.amazonaws.com is an alias for ec2-12-123-12-12.eu-west-1.compute.amazonaws.com.
ec2-12-123-12-12.eu-west-1.compute.amazonaws.com has address 12.123.12.12The reader endpoint works in a similar fashion, with the exception that it's backed by a Round-Robin DNS record pointing to the underlying database instances.
This explains why we were getting some errors during the failover operation: there is a rather large window of time (10-15 seconds) during which the cluster is adjusting to the new topology and DNS records are switched to reflect it. As you can imagine, DNS manipulation and propagation is not an atomic operation, hence the errors.
Scaling procedures
Once we gathered more information with this small research, we defined four different processes to scale our platform while minimizing the impact on our users. Let's have a look at them.
Horizontal scaling of the read cluster
This means adding or removing nodes to our read cluster to increase our read capacity.
Scaling out
Scaling out is really easy: If you use the AWS Console, you can pick your cluster and choose the Create New Aurora Replica option. In our case, a new read replica takes ~7 minutes to be ready, and this operation doesn't cause downtime of any sort. The new node will not be added to the reader DNS endpoint until fully ready.
Scaling in
This is actually a bit tricky. If we have 3 reader instances, and we decide to terminate one of them, the DNS round-robin will propagate with a certain delay, resulting in traffic being delivered to a dead database instance during a certain period of time.
Due to that, we decided to use an additional DNS record in Route53. This DNS record is the hostname applications normally connect to. It normally points to the cluster reader endpoint, except during a scale-in operation. In that case, we temporarily point it to a specific database reader instance, while others are being deleted.
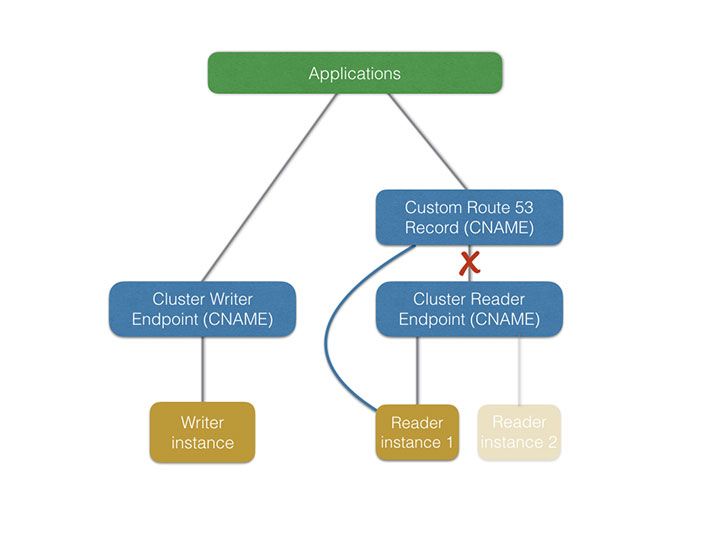
In this way we have exact control over the node where the read traffic is routed to, instead of relying on DNS propagation.
Vertical scaling of the writer node
Since Amazon Aurora is not multi-master, if we need more write capacity, we need to change the writer instance type. This means that we need to create a new Aurora instance with a higher capacity and then promote it to the writer role.
Scaling up
To have more control over the scale-up process, we usually create a new node with more capacity (let's name it new_master). It will be given the tier 0 which means it'll be the first candidate for promotion to the writer role. As explained in the scale-out section, this process takes ~7 minutes with our main database.
After that, we perform a manual failover on the cluster, which will promote new_master to writer. Due to DNS propagation delay, it's possible to see some errors during a window of 10-15 seconds (but your application is resilient to these errors, isn't it? :p)
Scaling down
This process is the inverse of scaling up. We only modify our old_master instance to have tier 0, and perform the cluster failover. Again, it's possible to see some errors during a 10-15 second window.
Final conclusions
Amazon Aurora clusters are managed with CNAME records which point to database instances. It is important to understand how they work to be able to minimize the impact of failover operations.
Having an additional Route53 record gives us more control during the scale-in operation, and it doesn't make the architecture more complex.
We're currently performing these processes manually, which means we're still not 100% satisfied with the solution. We have some ideas, but if you have any suggestions, feel free to leave a comment! Also, if you happen to be interested in this sort of scalability and reliability topics, keep in mind that we're hiring :-)